By Varun Patel, Founder & CEO of Crawlify | 30/06/2026 | 12 min read
Build vs. Buy for Pricing Data: The Real 3-Year Cost of an In-House Scraping Team
A US data engineer costs $123K–$137K in base pay. Bright Data charges $499–$10K/mo. Apify's real bills run $200–$1,500/mo after overage. The honest 3-year TCO of an in-house pricing-data team versus a managed pipeline, with the numbers.
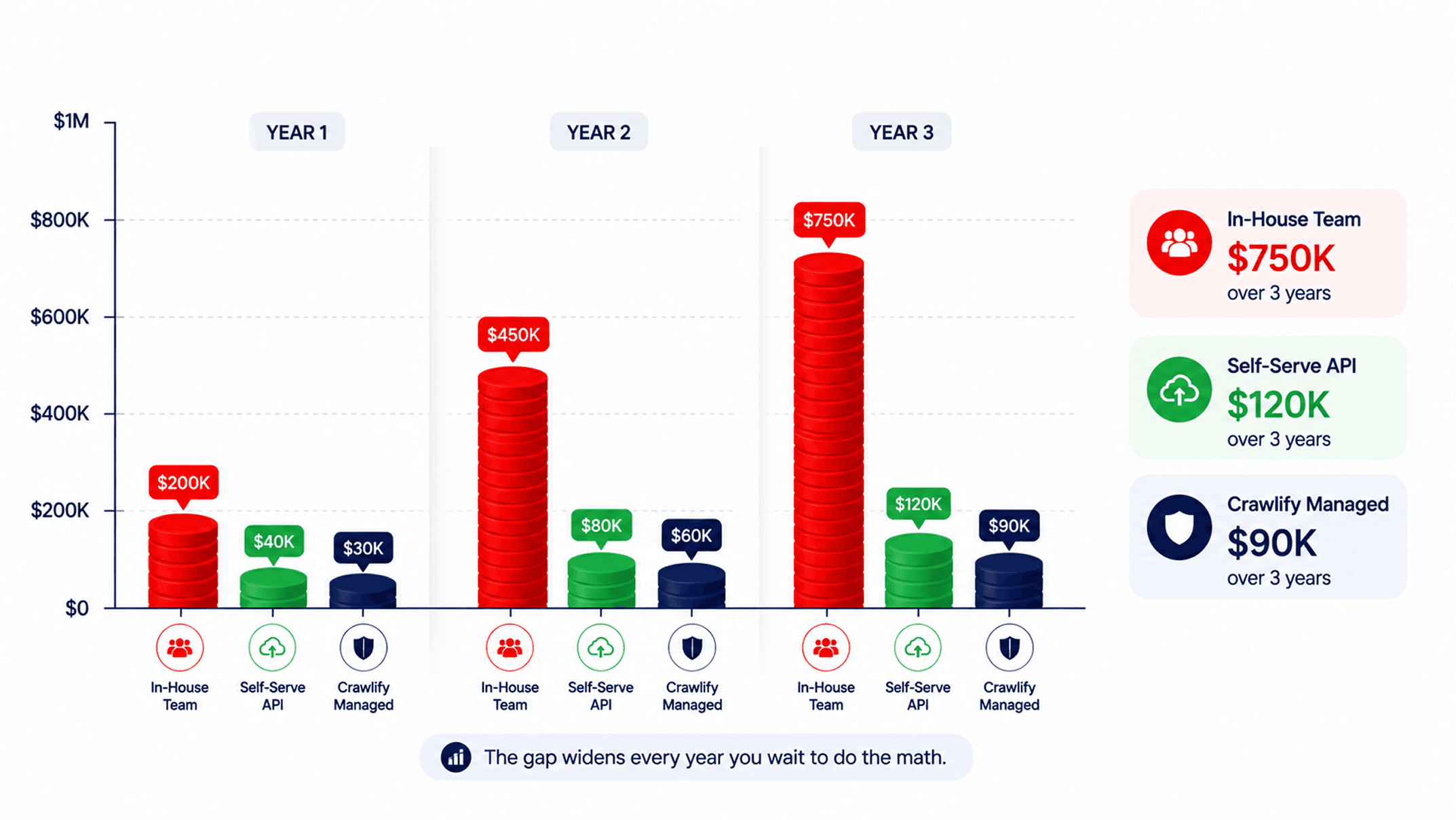
TL;DR — A US data engineer costs $123K–$137K in base pay (Indeed, ZipRecruiter, Salary.com, 2026). Loaded cost lands around $150K–$200K all-in. You need two to three of them to run a production pricing-data scraping operation. Add Bright Data or Apify infrastructure ($200–$10K/month) and 40–60 percent of an engineer's week absorbed by maintenance. Three-year TCO on the in-house team is $750K–$1.1M before the first silent-failure incident. A managed pipeline like Crawlify lands at $30K–$90K/year for the same scope. The math is not close.
The CTO objection I get every week
A CTO at a retail-analytics company told me last month: "Why am I paying two engineers to copy prices off a public web page?" Fair question. Public prices are free to look at. The work seems mechanical. The build-versus-buy reflex points to building, because building is what engineering teams do.
That objection is the question this post is built to answer. The copying isn't the work. The keeping-it-correct is the work. Once you put real numbers next to the maintenance cost of an in-house scraping team, the build-versus-buy reflex flips. The honest 3-year TCO of an in-house pricing-data operation is consistently 5–10 times the cost of a managed pipeline at the 10–150 employee company scale. The rest of this post shows where the gap comes from — and the small number of cases where building actually still makes sense.
SOURCE — US data engineer base pay (2026): Indeed $137,215; ZipRecruiter $129,716 (25th–75th percentile $114,500–$137,500); Salary.com $123,053; Glassdoor median total $133,010. Senior DEs $141,575–$160,000+. Source pages cited as of June 2026.
What an in-house pricing-data team actually costs
The headline salary number underestimates the real cost by roughly 30 to 50 percent. Fully-loaded engineering cost includes benefits, equipment, recruiting amortization, manager time, and overhead.
| Cost line | Year 1 | 3-year |
|---|---|---|
| 2 data engineers, base pay ($135K avg) | $270,000 | $830,000+ |
| Benefits + payroll tax (~30%) | $81,000 | $249,000 |
| Recruiting amortized (1 hire/yr at ~20% fee) | $27,000 | $81,000 |
| Equipment, software, manager time | $20,000 | $60,000 |
| Proxy + infra (Bright Data managed midline) | $36,000 | $108,000 |
| Silent-failure opportunity cost (conservative) | $25,000 | $75,000 |
| Total in-house TCO | ~$459,000 | ~$1.40M |
| Crawlify managed pipeline (typical pilot scope) | $30K–$60K | $90K–$180K |
All figures pre-tax, USD, 2026. Salary band uses an average of Indeed, ZipRecruiter, Salary.com, and Glassdoor data. Recruiting fee assumes one replacement hire across the 3-year horizon. Proxy/infra line uses Bright Data's mid-tier managed pricing ($3K/mo); custom enterprise contracts run higher (Vendr median $10K–$25K/mo).
A few things to notice in that table. The proxy and infrastructure line is small relative to people cost — building in-house doesn't avoid the proxy spend, it just adds it on top of salaries. The silent-failure line is intentionally conservative; the real downstream cost of bad pricing data at scale is higher. And the table assumes everything goes right — no one quits, no scrapers break catastrophically, no site redesigns require a sprint of rework.
Why two engineers, not one
A serious pricing-data operation runs 24 hours a day across multiple time zones. A single engineer covering the entire scraper fleet means every site redesign, every Cloudflare ruleset update, every schema drift event is on one person's pager. That works for a month. It does not work for a quarter.
Real in-house teams either staff for redundancy (two-plus engineers) or accept that the data feed will go silent during PTO, sick leave, and the inevitable departure window. The version of the math that uses one engineer is the version that explains the silent-failure line item growing every year.
What you actually pay self-serve providers
A common counter-argument: "we'll just use Bright Data or Apify directly and skip the headcount." That is a real path. It is also more expensive than the marketing copy implies, because both providers price the easy thing visibly and the production thing in fine print.
| Provider | Headline entry | Production-scale reality | Hidden costs |
|---|---|---|---|
| Apify | $29/mo Starter; $199 Scale; $999 Business | Real bills $200–$1,500/mo at moderate volume | CU overage, per-result Actor fees, $8/GB residential proxy |
| Bright Data | $499/mo Web Scraper API entry | $2K–$10K/mo serious usage; Vendr median $10K–$25K/mo | $5–$15/GB residential proxy, +50% Web Scraper API hike Jan 2025 |
| ScrapeHero | $550/site On-Demand; $1,500/mo Business | $8,000/mo Enterprise minimum | Per-site refresh charges; no published accuracy SLA |
| Zyte | Pay-as-you-go from $0.13 / 1K HTTP requests | Vendr-reported average ~$41K/yr annual contract | Managed Data tier starts ~$450–$1,000/mo (third-party reported) |
Sources: apify.com/pricing (May 2026); brightdata.com pricing pages; scrapehero.com pricing; zyte.com pricing; Vendr anonymized contract data; Tekpon, Use Apify, Prospeo independent reviews. Prices change frequently; verify on the vendor page before committing.
Self-serve pricing makes sense in two situations: you have an engineering team that's already proficient, or your data volume is small and stable. At a 10–150 person company with a real pricing-intelligence product, neither is reliably true — because the engineering team you have is the one whose time you want spent on your product, not on a scraper fleet.
The maintenance tax
The line item that breaks the in-house math is not the salary or the proxy spend. It is the percentage of engineering time absorbed by ongoing maintenance.
Industry observation across data-engineering teams running their own scrapers: maintenance grows from roughly 10 percent of an engineer's time in the first few months to 40–60 percent by year two. Every retailer redesign breaks selectors. Every anti-bot ruleset update breaks the proxy strategy. Every schema drift produces silent corruption that someone downstream eventually notices.
At a 50 percent maintenance load on two engineers, that's one full engineer's salary ($150K–$200K loaded) going to keep the pipeline running instead of doing product work. Three years in, you have spent the cost of two engineers to get the output of one. The opportunity cost is the cost.
Run the math on your pipeline. Send Crawlify a description of your current scraping setup (sources, volume, accuracy needs). Within five business days we send back an apples-to-apples 3-year TCO comparison — your in-house cost line by line, equivalent self-serve API cost, and a Crawlify managed quote. No credentials, no engineering hours. crawlify.ai/audit.
The Cloudflare wedge
One year ago tomorrow, on July 1, 2025, Cloudflare became the first major internet infrastructure company to block AI crawlers by default. About 20 percent of the web flipped from opt-out to opt-in overnight. HTTP 402 Payment Required became a real response code, and Cloudflare launched Pay Per Crawl as a marketplace for AI companies to pay site owners per scrape.
That change matters to the build-vs-buy math in two specific ways. First, the access cost rose for everyone — proxies that worked in June 2025 stopped working in July, and the residential-proxy spend that an in-house team can justify rose proportionally. Second, the operational surface area expanded: bot identity, crawler purpose declarations, and per-site policy negotiation became part of the job. None of that is bad for engineering teams — it is just more work that compounds the maintenance line.
A managed pipeline absorbs that supply-side shift. The customer sees the same data on the same schedule; the access cost is the provider's problem. An in-house team sees the supply-side shift directly on its incident channel, and on its proxy bill.
SOURCE — Cloudflare's July 1, 2025 announcement, official Cloudflare press release. Pay Per Crawl uses HTTP 402 Payment Required. Cloudflare protects approximately 20 percent of the web. Crawl-to-refer ratios for AI bots, including ClaudeBot peaking near 70,900:1 in mid-June 2025, are from Cloudflare's own Radar data.
Where in-house actually still makes sense
Not every team should buy. Four specific situations make an in-house build defensible:
Extreme scale. You operate at very large extraction volumes — 10M+ records per day, thousands of sources — where unit economics favor amortized infrastructure investment.
Proprietary sources. You're extracting from non-public or partner-only sources (logged-in dashboards, customer-supplied feeds) that managed providers cannot legally or technically reach.
Regulatory or data-residency constraints. You're in a regulated environment (finance, healthcare) where data residency, on-prem processing, or audit-trail control requires owning the pipeline.
Data extraction is your core competency. The data acquisition is the product. If your company's differentiation is being the world's best scraper for one specific vertical, owning that core capability is correct.
At a 10–150 person pricing-intelligence company, none of those four typically apply. The engineering time you have should be spent on the product that uses the data, not the pipeline that fetches it.
A 5-question decision framework
Before committing to either path, walk through these five questions with whoever holds the budget:
What percentage of your engineering team's time would you accept being absorbed by scraper maintenance in year two?
If your single scraping engineer resigned next quarter, how many weeks of degraded data would that cost?
What is your published or contractual accuracy SLA today — and would that change if you built in-house?
How would you find out a silent data corruption was running, and how many days would it take?
When Cloudflare's next default policy change ships, who handles the response — your engineers, or a vendor whose SLA covers it?
The honest answers to those five questions — written down, shared with the team — collapse most build-vs-buy debates inside a single meeting.
What a managed pipeline buys you that the spreadsheet doesn't show
The TCO comparison so far only counts dollars. The harder-to-quantify items matter at least as much:
Time to first reliable data. Compresses from quarters to weeks. A Crawlify pilot stands up in 5–14 days. Hiring two data engineers and getting them productive takes 4–6 months.
Engineering team focus. The provider absorbs the maintenance load and the schema-drift response. Your engineers get the week back.
Customer-facing accuracy. A published accuracy SLA (Crawlify's is 99.5%) means you can defend the claim to your own customers. An in-house team is hard to make contractually accountable to your downstream users.
Scalability without hiring. When the data layer is a vendor relationship, you can grow extraction volume by 5x in a month. With an in-house team, that's a hiring cycle.
What we charge, and why
Crawlify pilots typically run $2,500 to $5,500 per month at the start, scaled to source count and volume. Annual cost lands between $30K and $90K for a mid-sized pricing operation, comparable to one quarter of a single data engineer's loaded cost. Every contract includes the 99.5% verified field-accuracy SLA, the human-verification layer the ScholarMeet pipeline was built on, and a documented refund clause if the accuracy number is missed.
You can verify the math on your own numbers before deciding. We will send you a 3-year TCO comparison built on your headcount plan, current proxy spend, and source list, with the in-house side calculated using the same salary bands cited in this post. The audit is free and takes five business days.
Get the 3-year TCO on your scraping operation. Free comparison built on your numbers. crawlify.ai/audit or email hello@crawlifyai.com. Five business days, no credentials, no engineering hours on your side.
Frequently Asked Questions
Only at very large extraction volumes (10M+ records/day across thousands of sources) or with strict on-prem / regulatory requirements. At the typical 10–150 employee company scale, the math is consistent: managed wins by 5–10x on 3-year TCO.
Roughly $150K–$200K all-in (base + benefits + equipment + recruiting). One engineer is also not enough to cover a 24/7 production scraping operation.
DIY scraping got materially harder. About 20% of the web is now opt-in instead of opt-out, and HTTP 402 Payment Required is a real response code. The supply-side cost shifted toward managed providers.
They sell infrastructure: proxies, runtime, APIs. You still write the extractors, validate the fields, monitor the pipeline, and absorb the maintenance. Crawlify is the layer above that — we deliver verified data to your warehouse and absorb everything else.
Yes. The free 5-day accuracy audit is the right starting point. From there, pilots typically begin at the $2,500/month tier with one or two sources before expanding.

Varun Patel
Founder & CEO of Crawlify
Varun Patel is the CEO of Xillentech and the founder of Crawlify.ai. He writes about managed data pipelines, web-data quality, and the operational realities of running data products.